
MicroProfile OpenAPI—Code First
Working with MicroProfile OpenAPI
You're given the task of writing a microservice AND providing a documentation in OpenAPI format. You already know that there are two main approaches:
- design-first : write the OpenAPI document (a.k.a. the
openapi.yamlfile) and then generate the code- code-first : write the code, using OpenAPI annotations, and then generate the OpenAPI document
Which approach do you choose?
That was the short teaser description of my talk at Eclipsecon 2019.
Over the past four years I have continued to work with OpenAPI interfaces (both as an interface author and interface consumer) and my personal favourite was and still is the design-first approach.
Read on if you want to know why; this article covers the code first approach and a second article about the design-first approach will follow shortly.
Short Introduction to MicroProfile OpenAPI
OpenAPI is a standard to describe an HTTP API (also known as web services API or REST API) independently from a specific programming-language. The current version is 3.1.0, but this article uses version 3.0.3 as many tools don't support 3.1 yet.
Eclipse MicroProfile (MP) is a collection of specifications for aspects of Java microservices and is implemented in many Java frameworks such as OpenLiberty, Wildfly, Payara, Helidon, Quarkus and several others.
Eclipse MicroProfile OpenAPI defines how a JAX-RS microservice can expose its API definition. From a simplistic view point (scope of this article) it defines
- an endpoint (
/openapi) where the OpenAPI document of a service can be retrieved with an HTTP GET request - a set of Java Annotations that serve as input mechanism to generate an output OpenAPI document
- how existing OpenAPI files can be integrated into the output OpenAPI document
There are two main approches on how to work with MP OpenAPI:
Code First where the MP framework analyses the code to assemble the output OpenAPI
document. To get more than just a skeleton document with this approach, the code must
be explicitly annotated, e.g. with @OpenAPIDefinition, @Schema, @RequestBody
or @APIResponse to name just a few.
Design First where an existing OpenAPI document serves as input and the code is written
to match the existing document (usually by generating parts of the code from the OpenAPI
document); the OpenAPI document is then added to the microservice as static document that
can be served at the /openapi endpoint without further code analysis.
A Mini Service
All the examples shown use a very minimalistic fictitious service "txproc". It has
- two endpoints (
/purchaseand/pincheck) - two small request body structures (
PurchaseAuthRequestandPinCheckRequest) that have some shared fields
Here's an example request body PurchaseAuthRequest of the /purchase endpoint:
{
"uuid": "aaaaaaaa-bbbb-cccc-dddd-012345678901",
"pan": "4244333322221111",
"emvTags": {
"84" : "A0000000041010",
"9F1A" : "250"
}
}
and an example request body PinCheckRequest of the /pincheck endpoint:
{
"uuid": "aaaaaaaa-bbbb-cccc-dddd-012345678901",
"pan" : "4244333322221111",
"pinBlock": "magic"
}
The two (highlighted) fields uuid and pan are present in both request bodies
in order to show for both approaches how the documentation for these two fields
can be reused (instead of just being duplicated).
The source code of the example service is available on GitHub and the implementation uses the Quarkus framework. It is easily possible to run the service with another framework, Quarkus is just the one I'm most familiar with.
Code First
Actors of the Code First approach:
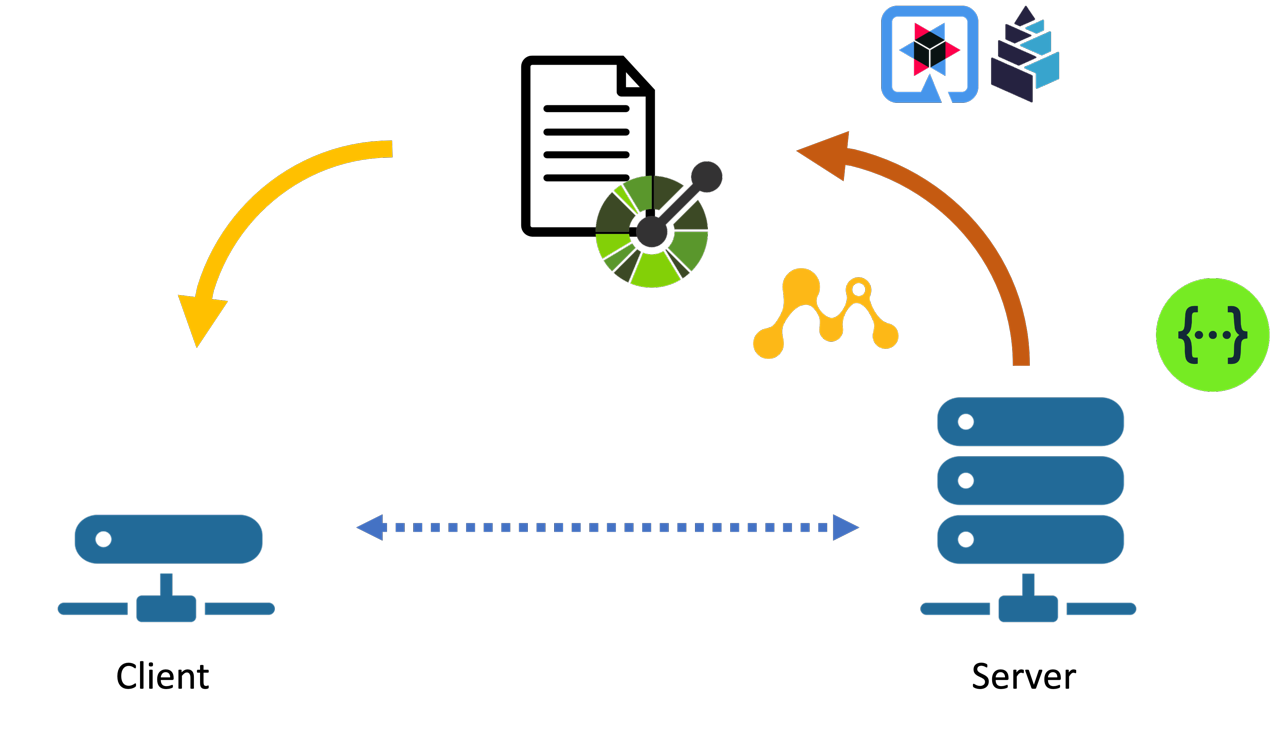 Code First: the OpenAPI document is generated from the code
Code First: the OpenAPI document is generated from the code
Legend
![]() Quarkus is the framework powering the microservice running on the server
Quarkus is the framework powering the microservice running on the server
![]() SmallRye is the MicroProfile implementation used by Quarkus
SmallRye is the MicroProfile implementation used by Quarkus
![]() denotes the OpenAPI document format served at
denotes the OpenAPI document format served at /openapi
![]() MicroProfile is one of two engines scanning the code for OpenAPI annotations
MicroProfile is one of two engines scanning the code for OpenAPI annotations
![]() Swagger is the other scanning engine
Swagger is the other scanning engine
The accompanying source code has two example projects for the code first approach:
- Using the SmallRye OpenAPI integration of Quarkus to build the OpenAPI document
- Using the Swagger Maven Plugin
to build the OpenAPI document (and Quarkus just to serve it at
/openapi)
From Annotation to openapi.yaml
Here's how the Java class PinCheckRequest for the /pincheck request body is annotated
to generate the OpenAPI document from code ("Code First" approach):
1@Schema(description = "Request for checking a PIN")
2public class PinCheckRequest {
3
4 @Schema(description = Model.UUID)
5 @NotNull
6 UUID uuid;
7
8 // the class Pan already carries a @Schema annotation
9 @NotNull
10 Pan pan;
11
12 @Schema(description = """
13 Encrypted binary data containing a PIN
14
15 Fieldcode: C003
16 """)
17 @NotNull
18 String pinBlock;
19}
On lines 1, 4 and 12..16 the MicroProfile @Schema annotation defines the description of the
PinCheckRequest schema (as classes/structures are called in an OpenAPI document)
and of its properties. Lines 12..16 show how to have a multiline description using
Java 15 text blocks.
Note that on line 4 the description references a string constant Model.UUID
in another class, allowing to use the same description also for the uuid field
of the request body of the other endpoint.
As the class Pan is defined in the same project and has itself a @Schema annotation,
the pan field should not carry a @Schema annotation (line 8).
The @NotNull annotations (lines 5, 9 and 17, from
Jakarta (Bean) Validation)
are translated into OpenAPI required: properties.
See here is the PinCheckRequest part of the generated OpenAPI document:
With SmallRye/Quarkus:
PinCheckRequest:
description: Request for checking a PIN
required:
- uuid
- pan
- pinBlock
type: object
properties:
uuid:
description: Unique ID of the request
type: string
allOf:
- $ref: '#/components/schemas/UUID'
pan:
$ref: '#/components/schemas/Pan'
pinBlock:
description: |-
Encrypted binary data containing a PIN
Fieldcode: C003
type: string
Pan:
title: PAN (Primary Account Number)
description: The number embossed on credit cards
type: string
UUID:
format: uuid
pattern: "[a-fA-F0-9]{8}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{12}"
type: string
With the Swagger Maven Plugin:
PinCheckRequest:
description: Request for checking a PIN
required:
- pan
- pinBlock
- uuid
type: object
properties:
uuid:
description: Unique ID of the request
format: uuid
type: string
pan:
title: PAN (Primary Account Number)
description: The number embossed on credit cards
type: string
pinBlock:
description: |-
Encrypted binary data containing a PIN
Fieldcode: C003
type: string
The two variants are almost identical, except that SmallRye/Quarkus creates sub schemas
for Pan and UUID, and that only SmallRye/Quarkus uses a regex pattern for the UUID
(though this might be redundant with format: uuid for most OpenAPI tools).
Review of the Code First Approach
When you'd like to have some Javadoc for interface classes, you have to document twice:
once with the @Schema annotation for OpenAPI and once with Javadoc. Note that the
PinCheckRequest class example above has no Javadoc. You would have to write e.g.
/**
* Request for checking a PIN
*/
@Schema(description = "Request for checking a PIN")
public class PinCheckRequest {
/**
* Unique ID of the request
*/
@Schema(description = Model.UUID)
@NotNull
UUID uuid;
// ... rest of the class
}
To document the same field (e.g. uuid or pan) for multiple endpoints/bodies you have a couple of options
- copy the
@Schemaannotation to every endpoint/body class, like the fielduuidin our example. By using a String constant (seeModel.UUID) you can at least avoid duplication of the description itself. - create a dedicated class for the field, like
Panfor the fieldpanin our example. In that case you place the@Schemaannotation directly on the class and no duplication is needed. But you have to configure the JSON framework properly to get a simple String when serializing the class (the example is using JSON-B and has a PanJsonAdapter.java for this) - use a class hierarchy to model your body classes. In our example you could create
a super class of
PurchaseAuthRequestandPinCheckRequestthat contains theuuidfield.
At least with Java 15+ you've now the possibility for nice multiline documentation.
In the old source code from 2019 (with Java 11) the field pinblock was documented
with \ns to get a multiline documentation (compare to the listing above):
public class PinCheckRequest {
@Schema(description = "Encrypted binary data containing a PIN"
+ "\n\nFieldcode: C003")
@NotNull
String pinBlock;
}
Code First Gotchas
In the 2019 talk I mentioned the following gotchas:
SchemaType.STRING
Using type=SchemaType.STRING for classes where you configured the JSON
serialization to result in a single String, i.e. to have this request body
using the Pan class:
{
"uuid": "aaaaaaaa-bbbb-cccc-dddd-012345678
"pan" : "100000000042",
"pinBlock": "magic"
}
you'd annotate it as follows, using type=SchemaType.STRING:
@Schema(title = "PAN (Primary Account Number)",
description = "The number embossed on credit cards",
type = SchemaType.STRING)
public class Pan {
private String pan;
// some methods
}
In 2019 (with Quarkus 0.25) this resulted in the following OpenAPI excerpt
1 properties:
2 pan:
3 title: PAN (Primary Account Number)
4 description: The number embossed on credit cards
5 type: string
6 properties:
7 pan:
8 type: string
Note the nested properties at lines 6-8 which just shouldn't be there
Even in 2023 (upto Quarkus 3.4) the generated OpenAPI was still wrong:
1PinCheckRequest:
2 properties:
3 pan:
4 $ref: '#/components/schemas/Pan'
5Pan:
6 $ref: '#/components/schemas/Pan'
Note the self-referencing $ref in the Pan schema. This issue (smallrye-open-api #1565) was finally fixed for Quarkus 3.5:
1PinCheckRequest:
2 properties:
3 pan:
4 $ref: '#/components/schemas/Pan'
5Pan:
6 title: PAN (Primary Account Number)
7 description: The number embossed on credit cards
8 type: string
UUID
In 2019 the java.util.UUID class had the same problem with type=SchemaType.STRING
as explained above for the class Pan.
This problem is not present anymore in 2023, and the class UUID (as it is a Java standard class)
is now processed specially (i.e. type = SchemaType.STRING not needed anymore); SmallRye/Quarkus
is using a regex pattern and format: uuid (which strictly speaking is not defined, but allowed by the
OpenAPI 3.0.3 spec:
Formats such as "email", "uuid", and so on, MAY be used even though undefined by this specification),
while Swagger only uses format: uuid without any regex pattern.
1UUID:
2 format: uuid
3 pattern: "[a-fA-F0-9]{8}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{12}"
4 type: string
Enums
With Quarkus 0.x in 2019 it was not possible to put the @Schema annotation
onto an enum type, this has been fixed in the meantime.
References
Another SmallRye/Quarkus quirk of 2019 was the inlining of non-toplevel schemas,
e.g. for class PurchaseAuthRequest { EmvTags emvTags; } this excerpt was generated:
1components:
2 schemas:
3 PurchaseAuthRequest:
4 description: Request for authorizing a Purchase
5 properties:
6 emvTags:
7 description: Collection of EMV tags
8 // properties left out
9 title: EmvTags
10 type: object
Now in 2023 the result is referencing a scheme as expected:
1components:
2 schemas:
3 PurchaseAuthRequest:
4 description: Request for authorizing a Purchase
5 properties:
6 emvTags:
7 $ref: '#/components/schemas/EmvTags'
8 EmvTags:
9 description: Collection of EMV tags
10 // properties left out
11 title: EmvTags
12 type: object
Differences between Swagger and SmallRye/Quarkus
Both tool chains (SmallRye/Quarkus and Swagger Maven Plugin) are quite mature now. There are still a couple of differences however:
-
An annotation
@ApplicationPath("/api")is per default ignored by Swagger, while SmallRye/Quarkus prepends it to the paths:paths: /api/txproc/pincheck:This behaviour can be enabled in Swagger with
<alwaysResolveAppPath>true</alwaysResolveAppPath> -
Swagger creates
operationId:properties automatically (I didn't find a configuration option to deactivate them); with Quarkus you have to enable them withmp.openapi.extensions.smallrye.operationIdStrategy=METHOD -
SmallRye/Quarkus creates OpenAPI
tags from the class name containing the JAX-RS@Pathannotation automatically, with Swagger you have to explicitly add atags = {"My Class"}parameter to the@Operationannotation.
Next up
Stay tuned for the second article, detailing the design-first approach. If you'd like to know about its publication, follow me on Mastodon.